SHAP
SHAPとは
SHAPはSHapley Additive exPlanationの略で、機械学習分野で使われる説明可能なAI(XAI)のアルゴリズムです。
Shapley(シャープレイ)は人物名、Additiveは「添付の、追加の」の意味です。(-itiveは「-の性質の」を意味する接尾辞)
SHAPはシャープレイの考案したシャープレイ値の理論を機械学習に応用したものです。
SHAPを使うことで個々の推論結果に対してどの特徴量の影響が大きいかを説明できます。
シャープレイとは
Shapley values(シャープレイ値)を1953年のゲーム理論関係の論文で考案した人物です。
シャープレイ値とは
シャープレイ値は協力ゲーム(kaggleコンペ等)での個人の貢献度を数値化したものです。
例えばある協力ゲームに以下の表の前提のもとでAとBとCで参加した場合、A、B、Cのシャープレイ値は順に20.83、35.83、33.34となります。(足すと90になる)
この値を比較することで各人の貢献度が分かります。(Cさんは個人能力は高いが貢献度は低い等)
プレーヤー |
バリュー |
説明 |
|---|---|---|
A |
10 |
Aが単独参加時に獲得するバリュー |
B |
20 |
Bが単独参加時に獲得するバリュー |
C |
25 |
Cが単独参加時に獲得するバリュー |
A, B |
40 |
AとBで参加時に獲得するバリュー |
A, C |
30 |
AとCで参加時に獲得するバリュー |
B, C |
50 |
BとCで参加時に獲得するバリュー |
A, B, C |
90 |
AとBとCで参加時に獲得するバリュー |
使い方
shapのパッケージをインストールし、
pip install shap
何かしらのモデルを作成します。
import pandas as pd
import shap
import xgboost
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
x_train = df
y_train = data.target
x_tr, x_va, y_tr, y_va = train_test_split(x_train,
y_train,
test_size=0.2,
shuffle=True,
stratify=y_train,
random_state=123)
model = xgboost.XGBRegressor().fit(x_tr, y_tr)
shapのAPIを使い予測値を計算します。
Explainerはモデル非依存なの(Explainer、KernelExplainer等)とモデル依存(TreeExplainer、DeepExplaier等)なのがあります。
モデル非依存なのは、その代わりに計算時間がモデル依存のより長くなるようです。
explainer = shap.Explainer(model)
shap_values = explainer(x_va)
後はshapでグラフ化のAPIが用意されているので、それらを使えば個々の推論結果に対してどの特徴量が重要かを確認できます。
# 1件目をウォーターフォールな図で表示
shap.plots.waterfall(shap_values[0])
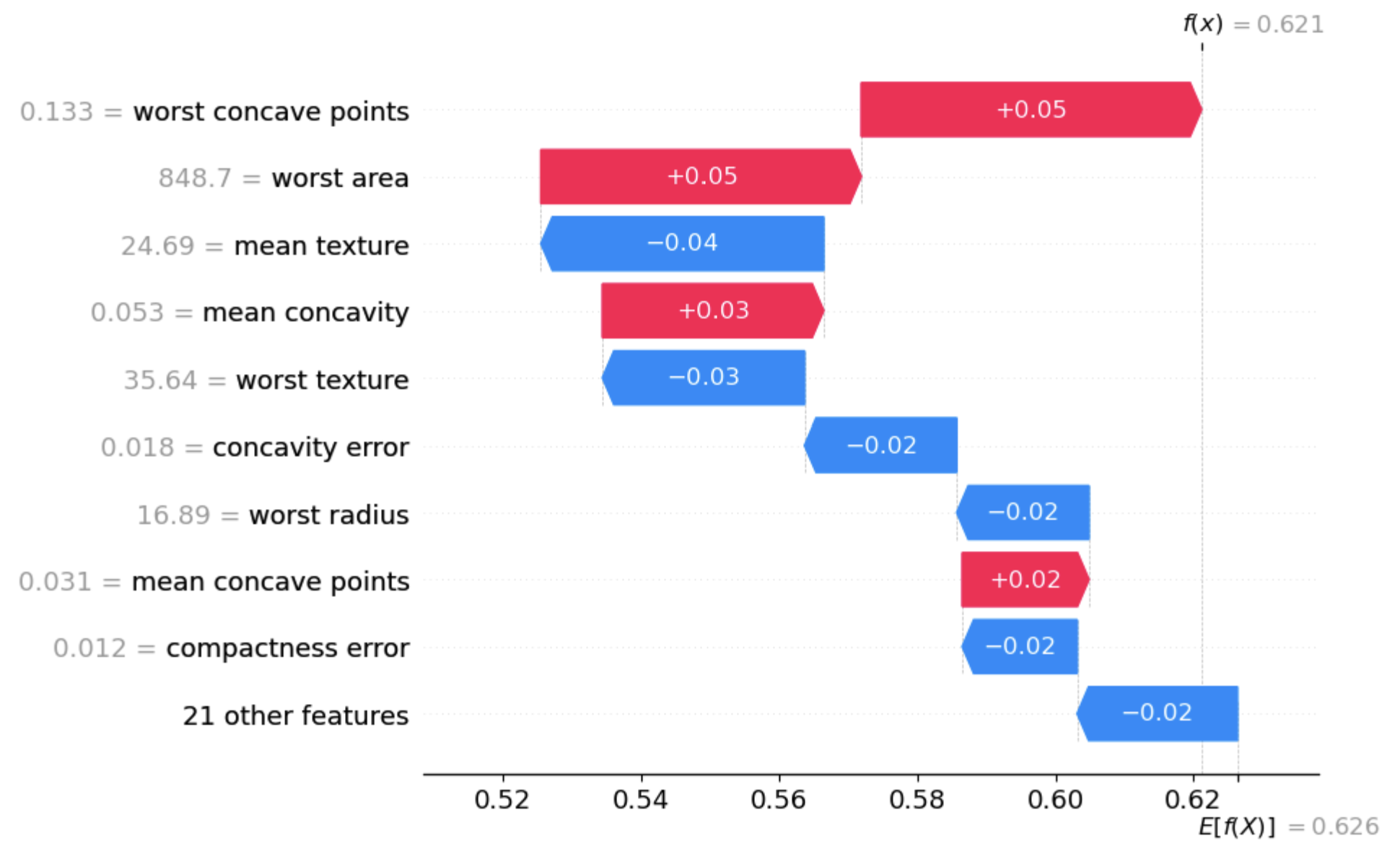
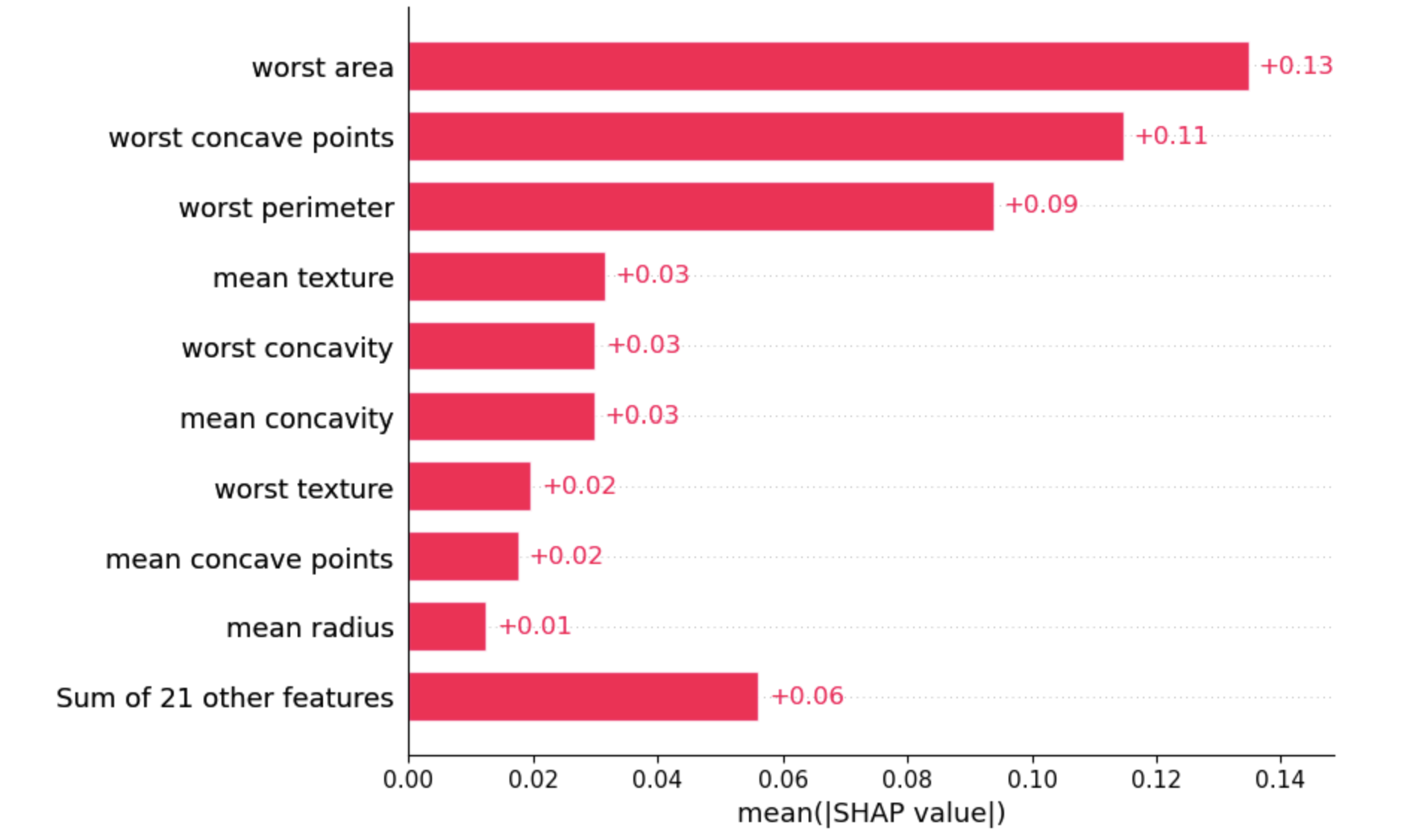
また個々の推論結果だけでなく、modelのfeature_importanceのように入力データ全体に対してどの特徴量が重要かを確認できます。
# 全体での表示
shap.plots.bar(shap_values)
制約
特徴量が多いデータには不向き:シャープレイ値の計算量は2のn乗のオーダーなので特徴量が多いほど計算に時間がかかる(SHAPは工夫して計算量を減らしているらしい)
ヒューマンフレンドリーでない:非技術者にとっては必ずしも分かりやすくない
APIがやや難あり:shapのグラフ表示関係のAPIはmodelによってエラー(shap_valuesのデータ型関係)となる場合があった(lgbmで確認)